Machine Learning
- MLlib overview
- Collaborative filtering

ALS too advanced! Let's go simpler
Let's write a recommendation engine
- Data: Movie ratings by MovieLens
- Algorithm: k-nearest neighbors
- Model: similarity graph
- Recommend!
Data
Ratings csv
userId,movieId,rating,timestamp
1,16,4.0,1217897793
6,24,1.5,1217895807
35,32,4.0,1217896246
70,47,4.0,1217896556
109,50,4.0,1217896523
345,110,4.0,1217896150
...
Movies csv
movieId,title,genres
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
4,Waiting to Exhale (1995),Comedy|Drama|Romance
5,Father of the Bride Part II (1995),Comedy
6,Heat (1995),Action|Crime|Thriller
7,Sabrina (1995),Comedy|Romance
...
Intuition
How do I find recommendations for an user?
- Find most similar users
- Pick movies from them he still didn't watch
Parse data
# load file and build user profiles
fileName = workingDir + "ratings.csv"
userProfiles = sc.textFile(fileName) \
.filter(lambda line: not 'userId' in line) \
.map(buildRatingFromLine) \
.groupBy(lambda profile: profile['user']) \
.map(buildProfileFromGroup) \
.cache()
def buildRatingFromLine(l):
fields = l.split(',')
return {
'user' : fields[0],
'movie' : fields[1],
'rating': float(fields[2])
}
def buildProfileFromGroup(g):
profile = {}
for rating in g[1]:
movieId = rating['movie']
profile[movieId] = rating['rating']
return {
'user' : g[0],
'profile': profile
}
list of user profiles
[
{
'user' : 216,
'profile': {
'10': 3.5,
'34': 5.0,
...
}
},
...
]
Similarity graph
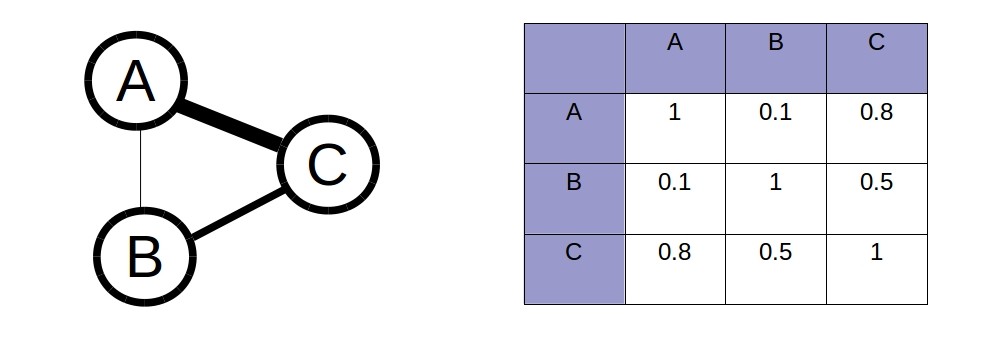

# compute similarity between users' profiles
similarityGraph = userProfiles.cartesian(userProfiles) \
.map(computeSimilarity) \
.filter(lambda similarity: similarity != None) \
.cache()
def computeSimilarity(twoUsers):
userA = twoUsers[0]
userB = twoUsers[1]
# don't compare a user with himself
if(userA['user'] == userB['user']):
return None
userAprofile = userA['profile']
userBprofile = userB['profile']
moviesRatedByA = set(userAprofile.keys())
moviesRatedByB = set(userBprofile.keys())
moviesBothUsersRated = moviesRatedByA.intersection( moviesRatedByB )
moviesRated = moviesRatedByA.union( moviesRatedByB )
moviesOnlyBRated = moviesRatedByB.difference( moviesRatedByA )
similarity = float( len(moviesBothUsersRated) ) / float( len(moviesRated) )
return {
'user' : userA['user'],
'other': userB['user'],
'similarity' : similarity,
'recommendations': list(moviesOnlyBRated)
}
list of one-to-one recommendations
[
{
'user' : 216,
'other': 306,
'similarity' : 0.83,
'recommendations': [236, 101, 45, ...]
},
...
]
k-nearest neighbors
get k most similar profiles for each user
# take recommendations from the most similar users
k = 10
finalRecommendations = {}
for i, userId in enumerate(userIds):
kNearestNeighBours = similarityGraph.filter(lambda rec: rec['user'] == userId) \
.sortBy(lambda rec: rec['similarity'], ascending=False) \
.take(k)
finalRecommendations[userId] = getRecommendationsFromKNN( kNearestNeighBours )
which movies are recommended by my neighbors?
def getRecommendationsFromKNN(kNearestNeighBours):
recommendations = []
for i, neighbour in enumerate(kNearestNeighBours):
recsFromUser = set(neighbour['recommendations'])
if i == 0:
recommendations = recsFromUser
else:
unionSet = recommendations.intersection( recsFromUser )
if len(unionSet) > 1:
recommendations = unionSet
return list( recommendations )
list of ready recommendations!
{
'216': [ '94', '402', '423', '232' ],
'344': [ '345', '2', '60', '142', '96' ],
...
}
(to be loaded on DB)
Limitations...
- not considering rating [0,5]
- not looking into movies' genre
- not looking into movies at all
